[sw 사관학교 정글] [WEEK02] WIL 02주차 개발일지
[스택, 큐, 힙]
알고리즘
(파이썬 알고리즘, 기타: https://www.daleseo.com/python-priority-queue/)
선형탐색, 순차탐색(Linear search,Sequential search)
리스트 안에 있는 특정한 데이터를 찾기 위해 앞에서 부터 데이터를 하나씩 확인, 데이터를 따로 조작할 필요가 없어 단순하지만 비효율적임, 단방향으로 탐색을 수행하기 때문에 선형탐색(Linear search)라고 하기도 함
시간복잡도:O(n)
이분탐색, 이진탐색(binary search)
오름차순 정렬되어 있는 (이분탐색의 조건) 배열에서 데이터를 찾으려 시도할 때, 순차탐색처럼 처음 부터 끝까지 하나씩 모든 데이터를 체크하여 값을 찾는 것이 아니라 탐색 범위를 절반씩 줄여가며 찾는 Search 방법
시간복잡도:O(logN)
- 탐색 리스트가 정렬되어 있지 않다면 정렬
- left, right, mid 잡아줌(리스트 첫 번째는 left, 리스트 마지막은 right, 리스트 중간 값은 mid)
- *값보다 리스트의 인덱스로 잡는 것이 범용적
- mid 값과 찾고자 하는 값 비교
- mid 값이 더 크면 right 값을 mid-1, mid값이 더 작으면 left값을 mid + 1 로 세팅
- left > right가 될 때가지 반복
내가 생각하는 이분탐색의 구조!
def binary( 리스트, x):
메인 알고리즘
answer = 0
while start ≤ end:
mid = (start + end) //2
if 조건: -> binary 활용
answer = mid
start = mid + 1
else:
end = mid - 1
def binary_search(arr, value):
first, last = 0, len(arr)
while first <= last:
mid = (first + last) // 2
if arr[mid] == value:
return mid
if arr[mid] > value:
last = mid - 1
else:
first = mid + 1
arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result_index = binary_search(arr, 6)
print(result_index, arr[result_index])
# 5 6
- bisect 모듈
- 이진 탐색 알고리즘을 구현한 모듈
- 리스트에 순차적으로 접근해야 할 때 2개의 점의 위치를 기록하며 처리하는 알고리즘
백트래킹
현재 상태에서 가능한 모든 후보군을 따라 들어가며 탐색하는 알고리즘
스택
- 선입 후출
- 리스트를 만들어 구현
>>> stack = [4, 5, 6]
>>> stack.append(7)
>>> stack.append(8)
>>> queue
[4, 5, 6, 7, 8]
>>> queue.pop()
4
>>> queue.pop()
5
>>> queue
[6, 7, 8]
큐
- 선입 선출
[리스트]
>>> queue = [4, 5, 6]
>>> queue.append(7)
>>> queue.append(8)
>>> queue
[4, 5, 6, 7, 8]
>>> queue.pop(0)
4
>>> queue.pop(0)
5
>>> queue
[6, 7, 8]
[deque] - 데이터를 양방향에서 추가하고 제거할 수 있는 자료구조, popleft( ) 메서드를 활용하여 첫번째 데이터를 저거 할 수 있음, appendleft(x) 메서드를 사용하면 데이터를 맨 앞에서 삽입할 수 있음
>>> from collections import deque
>>>
>>> queue = deque([4, 5, 6])
>>> queue.append(7)
>>> queue.append(8)
>>> queue
deque([4, 5, 6, 7, 8])
>>> queue.popleft()
4
>>> queue.popleft()
5
>>> queue
deque([6, 7, 8])
우선순위 큐(Priority Queue)
- 데이터 추가는 어떤 순서로 해도 상관이 없지만, 제거될 때는 가장 작은 값을 제거 함
- 우선순위에 따라 처리하고 싶을 때 사용
- pop을 하게 되면 우선순위가 가장 높은 항목을 리턴하면서 삭제
- (우선순위가 높다 = 값이 작다)
- heapq(힙큐)모듈을 통해 구현 *밑에 이어서 정리
from queue import PriorityQueue
que = PriorityQueue() #PriorityQueue() 생성자를 이용해서 비어있는 우선순위 큐를 초기화
que.put(4)
que.put(1)
que.put(7)
que.put(3) #PriorityQueue() 클래스의 put()메서드를 이용해 우선순위 큐에 원소를 추가
que.get() #print(que.get()) -> 1
que.get() #print(que.get()) -> 3
que.get() #print(que.get()) -> 4
que.get() #print(que.get()) -> 7
그래프
그래프의 특징
- 그래프틑 네트워크 모델이다.
- 노드들 사이에 방향/무방향 경로를 가질 수 있다.
- 그래프틑 순환 혹은 비순환이다.
- 그래프틑 크게 방향 그래프와 무방향 그래프가있다
내가 생각하는 이분탐색의 구조!
def binary( 리스트, x):
메인 알고리즘
answer = 0
while start ≤ end:
mid = (start + end) //2
if 조건: -> binary 활용
answer = mid
start = mid + 1
else:
end = mid - 1
def binary_search(arr, value):
first, last = 0, len(arr)
while first <= last:
mid = (first + last) // 2
if arr[mid] == value:
return mid
if arr[mid] > value:
last = mid - 1
else:
first = mid + 1
arr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
result_index = binary_search(arr, 6)
print(result_index, arr[result_index])
# 5 6
- bisect 모듈
- 이진 탐색 알고리즘을 구현한 모듈
- 리스트에 순차적으로 접근해야 할 때 2개의 점의 위치를 기록하며 처리하는 알고리즘
백트래킹
현재 상태에서 가능한 모든 후보군을 따라 들어가며 탐색하는 알고리즘
스택
- 선입 후출
- 리스트를 만들어 구현
>>> stack = [4, 5, 6]
>>> stack.append(7)
>>> stack.append(8)
>>> queue
[4, 5, 6, 7, 8]
>>> queue.pop()
4
>>> queue.pop()
5
>>> queue
[6, 7, 8]
큐
- 선입 선출
[리스트]
>>> queue = [4, 5, 6]
>>> queue.append(7)
>>> queue.append(8)
>>> queue
[4, 5, 6, 7, 8]
>>> queue.pop(0)
4
>>> queue.pop(0)
5
>>> queue
[6, 7, 8]
[deque] - 데이터를 양방향에서 추가하고 제거할 수 있는 자료구조, popleft( ) 메서드를 활용하여 첫번째 데이터를 저거 할 수 있음, appendleft(x) 메서드를 사용하면 데이터를 맨 앞에서 삽입할 수 있음
>>> from collections import deque
>>>
>>> queue = deque([4, 5, 6])
>>> queue.append(7)
>>> queue.append(8)
>>> queue
deque([4, 5, 6, 7, 8])
>>> queue.popleft()
4
>>> queue.popleft()
5
>>> queue
deque([6, 7, 8])
우선순위 큐(Priority Queue)
- 데이터 추가는 어떤 순서로 해도 상관이 없지만, 제거될 때는 가장 작은 값을 제거 함
- 우선순위에 따라 처리하고 싶을 때 사용
- pop을 하게 되면 우선순위가 가장 높은 항목을 리턴하면서 삭제
- (우선순위가 높다 = 값이 작다)
- heapq(힙큐)모듈을 통해 구현 *밑에 이어서 정리
from queue import PriorityQueue
que = PriorityQueue() #PriorityQueue() 생성자를 이용해서 비어있는 우선순위 큐를 초기화
que.put(4)
que.put(1)
que.put(7)
que.put(3) #PriorityQueue() 클래스의 put()메서드를 이용해 우선순위 큐에 원소를 추가
que.get() #print(que.get()) -> 1
que.get() #print(que.get()) -> 3
que.get() #print(que.get()) -> 4
que.get() #print(que.get()) -> 7

그래프

그래프의 특징
- 그래프틑 네트워크 모델이다.
- 노드들 사이에 방향/무방향 경로를 가질 수 있다.
- 그래프틑 순환 혹은 비순환이다.
- 그래프틑 크게 방향 그래프와 무방향 그래프가있다
그래프 용어
- 정점(vertext) : 위치라는 개념
- 간선(edge) : 정점을 연결하는 선
- 인접 정점(adjacent vertex) : 간선에 직접 연결된 정점
- 차수(degree) : 한 정점에 연결된 간선의 수 (주로 무방향 그래프에서 사용)
- 입력 차수(in-degree) : 한 정점으로 들어오는 간선의 수 (주로 방향그래프에서 사용)
- 출력 차수(out-degree) : 한 정점에서 나가는 간선의 수(주로 방향그래프에서 사용)
- 사이클(cycle) : 한 정점에서 출발하여 시작했던 정점으로 돌아오는 경로
- 가중치 그래프 : 간선마다 가중치 값이 매겨져있는 그래프
그래프의 종류
무방향 그래프(Undirected Graph)
- 간선을 통해 양방향으로 갈 수 있다.
- 정점 A와 정점 B를 연결하는 간선은 (A,B), (B,A) 이다.
방향 그래프(Directed Graph)
- 간선에 방향성이 존재하는 그래프
- A -> B로 갈 수 있는 간선은 (A, B)로 표시한다.
가중치 그래프(Weighted Graph)
- 간선을 이동하는데 비용이나 가중치가 할당된 그래프
- 네트워크라고도 한다.
트리구조
- 여러 노드가 한 노드를 가리킬 수 없는 구조이다. 간단하게는 회로가 없고, 서로 다른 두 노드를 잇는 길이 하나뿐인 그래프
- 배열, 리스트, 스택, 큐와 같은 선형구조가 아닌 부모 자식의 관계를 갖는 계층형 그래프

트리의 특징
- 트리는 계층 모델이다.
- 트리는 비순환 그래프이다.
- 노드가 N개인 트리는 항상 N-1개의 간선을 가진다.
- 순회는 Pre-order, In-order, Post-order로 이루어진다.
- 트리는 이진트리, 이진 탐색 트리, 균형 트리, 이진 힙 등이 있다.
트리의 용어
- 루트 노드(root node) : 부모가 없는 노드, 트리는 하나의 루트 노드 만을 가진다.
- 단말 노드(leaf node) : 자식이 없는 노드
- 내부(internal) 노드 : 단말 노드가 아닌 노드
- 간선(edge) : 노드를 연결하는 선
- 형제(sibling) : 같은 부모를 가지는 노드
- 조상 노드(ancestors node) : 임의의 노드에서 루트 노드에 이르는 경로상에 있는 노드들 (D의 조상은 B, A이다)
- 노드의 크기(size) : 자신을 포함한 모든 자손 노드의 개수
- 노드의 깊이(depth) : 루트에서 어떤 노드에 도달하기 위해 커쳐야하는 간선 수
- 노드의 레벨(level) : 트리의 특정 깊이를 가지는 노드의 집합
- 노드의 차수(degree) : 각 노드에서 뻗어나온 가지의 수 (D의 차수는 2이다.)
- 트리의 차수(degree of tree) : 트리에서 가장 큰 차수
- 트리의 높이(height) : 가장 깊숙히 있는 노드의 깊이 (3)
트리의 종류
1. Binary Tree(이진 트리)
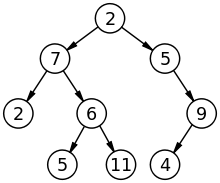
노드가 하나 이상의 자식을 갖게 되면 트리라고 부르는데 자식 노드가 최대 2개까지만 허용하는 트리를 이진트리라고 부릅니다.
2. Ternary Tree

3. Binary Search Tree(이진 탐색 트리)

다른 특별한 조건 없이 노드의 자식이 최대 2개씩만 붙으면 이진 트리라고 부르게 되는데, 이진 탐색 트리는 왼쪽 노드와 그 이하의 자식 노드들은 현재의 노드보다 작아야 하며 오른쪽 노드와 그 이하의 자식들은 현재의 노드 보다 큰 조건을 만족하게 된다. 그러므로 모든 값들이 노드들을 기준으로 두 가지 방향으로만 찾으면 되기 때문에 값을 찾는데 편리한 조건을 지니고 있다.
4. Complete Binary Tree(완전 이진 트리)

모든 노드들이 레벨 별로 왼쪽부터 채워져 있을 경우 완전 이진 트리라고 한다. 즉, 마지막 레벨을 제외한 서브 트리의 레벨이 같아야 하며 마지막 레벨이 왼쪽부터 채워져 있으면 완전 이진 트리라고 한다.

하나의 자식 노드를 가진 트리가 하나도 존재하지 않을 경우에 Full Binary Tree라고 한다. 노드들의 자식이 하나도 없거나 두 개의 자식으로만 구성될 경우이다.
6. Perfect Binary Tree

양 쪽으로 빈 공간 없이 모든 노드가 두 개의 자식을 가지며 레벨도 같을 경우를 말한다. 레벨의 개수를 n이라고 가정할 때 2^n - 1의 노드 개수를 가지게 된다.

노드

typedef struct Node{
int data;
Node *next;
}Node;
힙(Heap) → 트리 개념이 있기 때문에, 트리에 관한 공부를 선행학습한다
- 최대 힙(Max Heap)
- 최대 트리는 각 노드의 키 값이 그 자식의 키 값보다 크거나 같은(=작지않은) 트리이다
- 최소 힙(Min Heap)
- 최소 트리는 각 노드의 키 값이 그 자식의 키 값보다 작거나 같은(=크지않은) 트리이다
import heapq를 사용했을 때 기본적으로 최소힙이다. 최대힙은 -1 을 곱해서 구현 가능
∴ pop, push 단계에서 -1 만 곱해주면 됨
*출력시 -1 을 곱해서 원상복구
파이썬 표준입출력
stdin, stdout
집합자료형
- 집합 자료형 ≠ 리스트
- set() 을 이용하여 만들 수 있음
- 중복을 허용하지 않음
- 순서가 없음
기타
tuple → list
- list(())
list → tuple
- tuple(())
예외처리
- try : 실행코드(오류가 발생하나 보자!)
- except : 예외처리 코드(오류가 발생하면 이걸 실행해줘!)
- else : 예외처리할 오류가 없을때 실행되는 코드
- finally : 오류 발생여부 상관 없이 무조건 실행되는 코드
- raise : 오류를 일부러 발생시키기
pass continue break 차이점
Python 기본 문법에 있어 pass, continue break의 차이점을 알아보겠습니다.
- pass : 실행할 코드가 없는 것으로 다음 행동을 계속해서 진행합니다.
- continue : 바로 다음 순번의 loop를 수행합니다.
- break : 반복문을 멈추고 loop 밖으로 나가도록합니다.
pass
for i in range(10):
if i % 2 == 0:
pass
print(i)
else:
print(i)
print("Done")
0
1
2
3
4
5
6
7
8
9
Done
continue
for i in range(10):
if i % 2 == 0:
continue
print(i)
print(i)
print("Done")
1
3
5
7
9
Done
break
for i in range(10):
if i % 2 == 0:
break
print(i)
else:
print(i)
print("Done")
Done
PEP8
- 파이썬의 일관된 규칙가이드
- 클래스명 → (CamelCase)
- 함수명 → (snake_case)
# 나쁜 예시(카멜 명명법)
myHouseName = 'xi'
def myPhoneNumber():
print('010-1234-5678')
# 좋은 예시 (스네이크 명명법)
my_house_name = 'xi'
def my_phone_number():
print('010-1234-5678')
- 상수 → (snake_case) + 대문자
# 나쁜 예시
myName = 'Lin'
# 좋은 예시
MY_NAME = 'Lin'
- 괄호 → 띄어쓰기 금지
# 나쁜 예시
sandwich( egg[ 2 ], {ham: 3} )
# 좋은 예시
sandwich(egg[2], {ham: 3})
- 함수 호출 → 띄어쓰기 금지
# 나쁜 예시
sandwich (egg[2], {ham: 3})
# 좋은 예시
sandwich(egg[2], {ham: 3})
- 쉼표 → 띄어쓰기 금지
# 나쁜 예시
if x == 2 : print x , y ; x , y = y , x
# 좋은 예시
if x == 2: print x, y; x, y = y, x
- 할당 연산자 → 앞뒤로 각각 한개 씩 띄어쓰기
## 나쁜 예시
x=1
y=2
z=3
## 좋은 예시
x = 1
y = 2
z = 3
- 인라인 주석 → 되도록 사용 하지 않는게 좋음, 사용할 경우 실행 코드와 두칸 이상의 띄어쓰기를 해줌
# 나쁜 예시
my_house_name = 'xi' # 나의 집 이름
def my_phone_number(): # 내 전화번호
print('010-1234-5678')
# 좋은 예시
my_house_name = 'xi' # 나의 집 이름
def my_phone_number(): # 내 전화번호
print('010-1234-5678')
2차원 리스트
paper = []
for _ in range(N):
paper.append(list(map(int, input().split())))
paper = [list(map(int, sys.stdin.readline().split())) for _ in range(N)]
stack= []
for i in range(n):
stack.append(list(input()))
특정 모듈에 기능만 사용하고 싶을때
__name__ == "__main__"
sort랑 sorted 차이
sort는 반환값을 주지 않음